1. 简介
kafka 是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。
生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
kafka 对外使用 topic 的概念,生产者往 topic 里写消息,消费者从读消息。
为了做到水平扩展,一个 topic 实际是由多个 partition 组成的,遇到瓶颈时,可以通过增加 partition 的数量来进行横向扩容。单个 parition 内是保证消息有序。
每新写一条消息,kafka 就是在对应的文件 append 写,所以性能非常高。
kafka 的总体数据流是这样的:
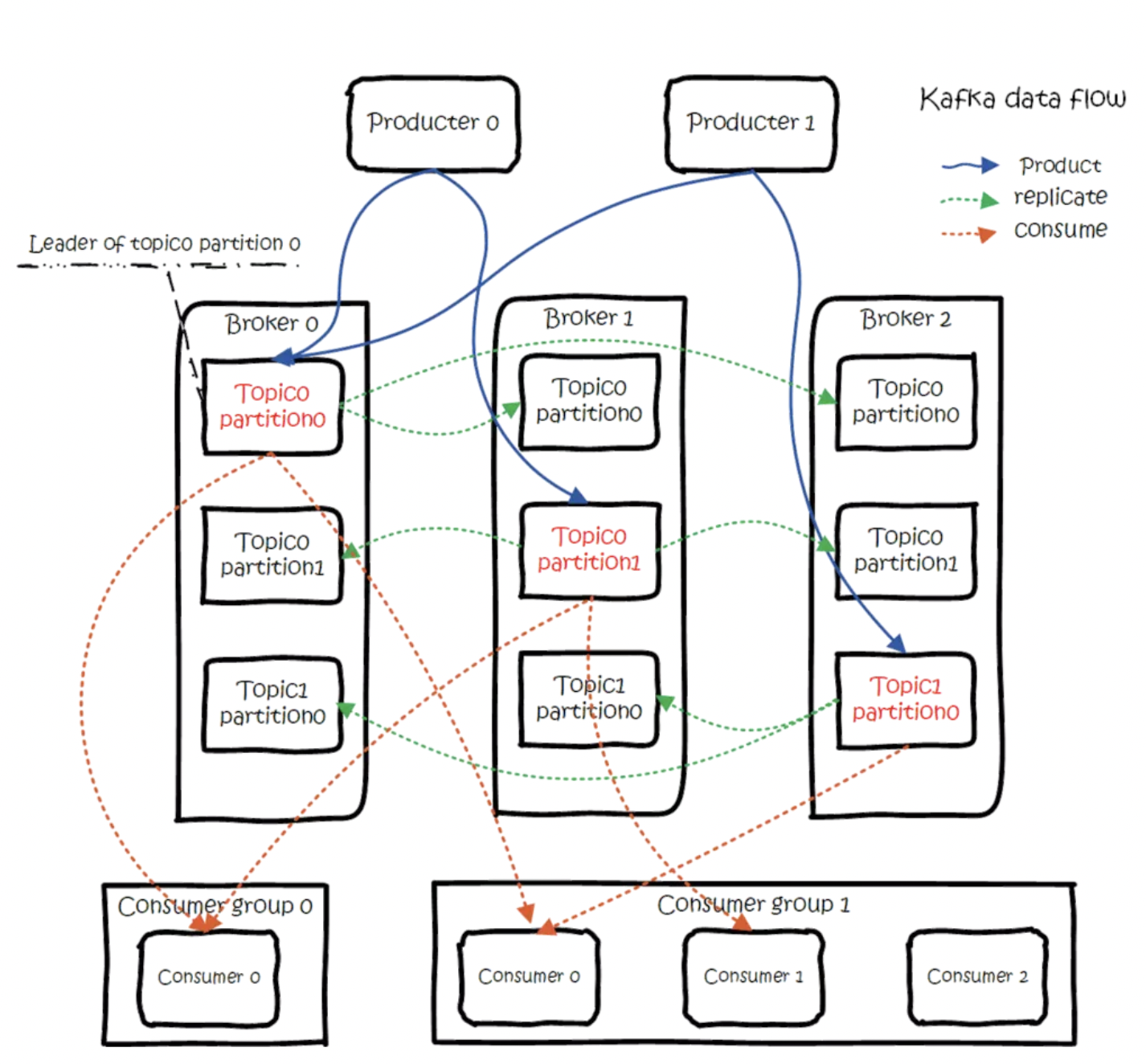
大概用法就是,Producers 往 Brokers 里面的指定 Topic 中写消息,Consumers 从 Brokers 里面拉去指定 Topic 的消息,然后进行业务处理。 图中有两个 topic,topic 0 有两个 partition,topic 1 有一个 partition,三副本备份。可以看到 consumer gourp 1 中的 consumer 2 没有分到 partition 处理,这是有可能出现的,下面会讲到。
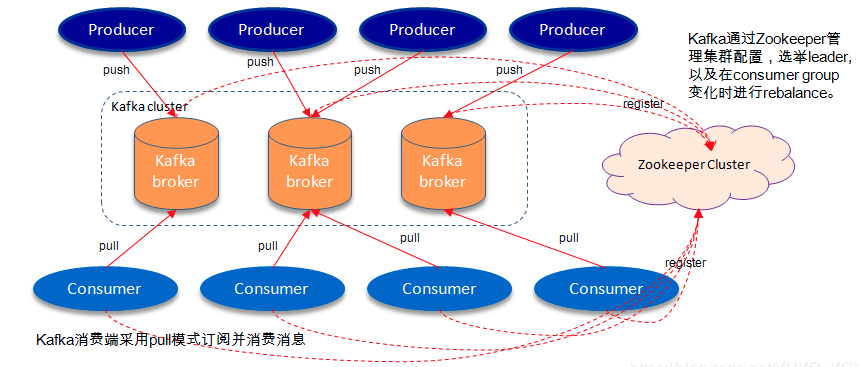
关于 broker、topics、partitions 的一些元信息用 zk 来存,监控和路由啥的也都会用到 zk。
kafka + zookeeper 架构如下:
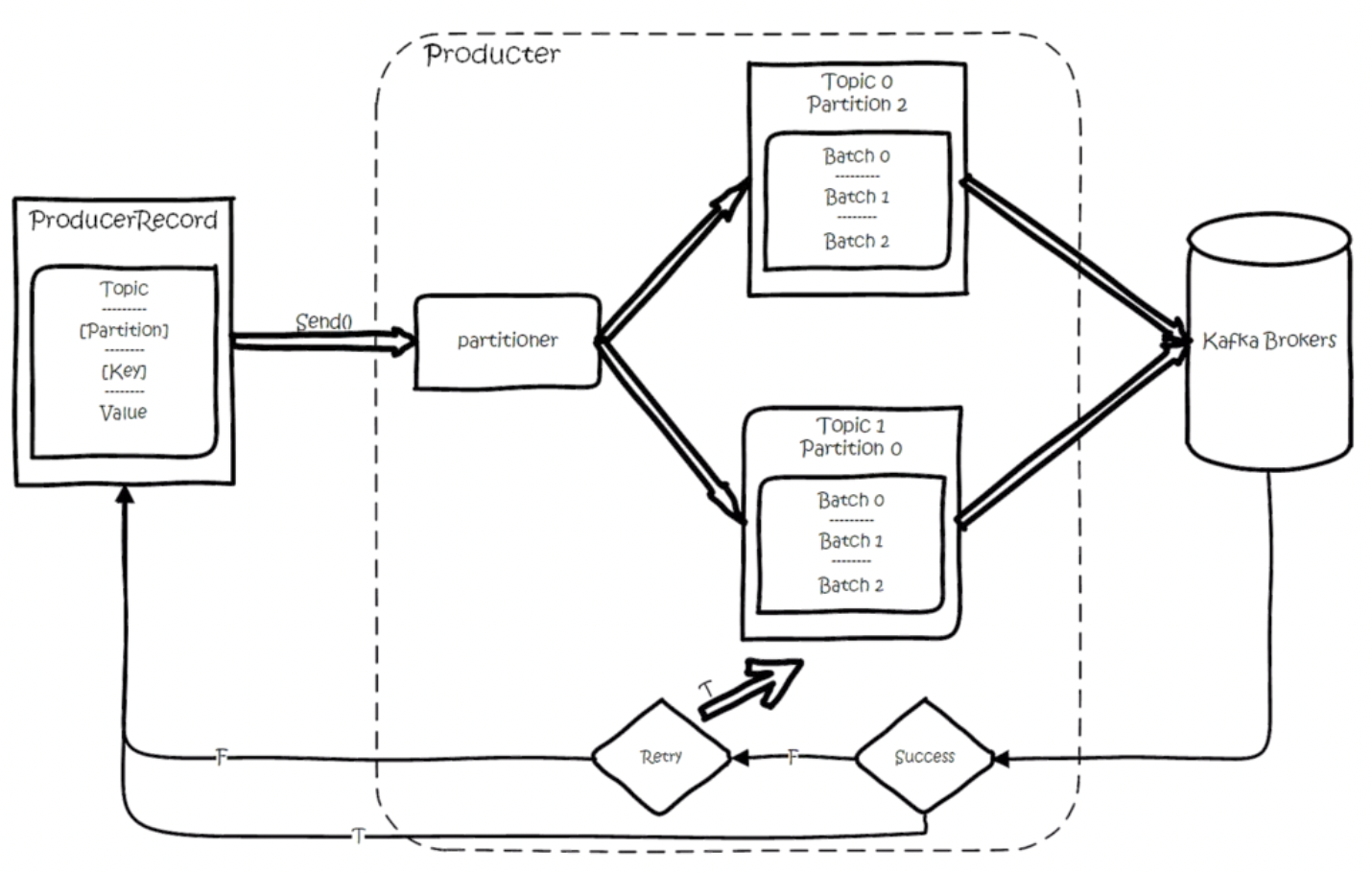
2. 生产
创建一条记录,记录中一个要指定对应的 topic 和 value,key 和 partition 可选。 先序列化,然后按照 topic 和 partition,放进对应的发送队列中。kafka produce 都是批量请求,会积攒一批,然后一起发送,不是调 send()就进行立刻进行网络发包。 如果 partition 没填,那么情况会是这样的:
- key 有填:按照 key 进行哈希,相同 key 去一个 partition。(如果扩展了 partition 的数量那么就不能保证了)
- key 没填:round-robin 来选 partition
这些要发往同一个 partition 的请求按照配置,攒一波,然后由一个单独的线程一次性发过去。
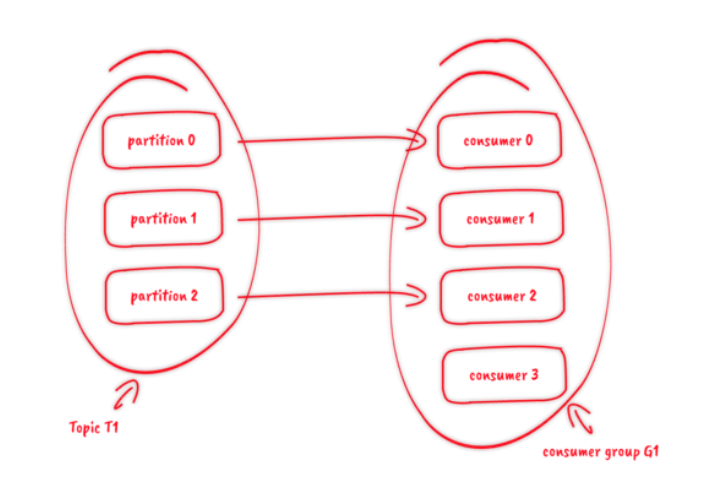
3. 消费
订阅 topic 是以一个消费组来订阅的,一个消费组里面可以有多个消费者。同一个消费组中的两个消费者,不会同时消费一个 partition。换句话来说,就是一个 partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。因此,如果消费组内的消费者如果比 partition 多的话,那么就会有个别消费者一直空闲。
4. 消息投递语义
kafka 支持 3 种消息投递语义
- At most once:最多一次,消息可能会丢失,但不会重复
- At least once:最少一次,消息不会丢失,可能会重复
- Exactly once:只且一次,消息不丢失不重复,只且消费一次(0.11 中实现,仅限于下游也是 kafka)
在业务中,常常都是使用 At least once 的模型,如果需要可重入的话,往往是业务自己实现。
4.1. At least once
先获取数据,再进行业务处理,业务处理成功后 commit offset。
1、生产者生产消息异常,消息是否成功写入不确定,重做,可能写入重复的消息
2、消费者处理消息,业务处理成功后,更新 offset 失败,消费者重启的话,会重复消费
4.2. At most once
先获取数据,再 commit offset,最后进行业务处理。
1、生产者生产消息异常,不管,生产下一个消息,消息就丢了
2、消费者处理消息,先更新 offset,再做业务处理,做业务处理失败,消费者重启,消息就丢了
4.3. Exactly once
思路是这样的,首先要保证消息不丢,再去保证不重复。所以盯着 At least once 的原因来搞。 首先想出来的:
生产者重做导致重复写入消息—-生产保证幂等性 消费者重复消费—消灭重复消费,或者业务接口保证幂等性重复消费也没问题
由于业务接口是否幂等,不是 kafka 能保证的,所以 kafka 这里提供的 exactly once 是有限制的,消费者的下游也必须是 kafka。所以一下讨论的,没特殊说明,消费者的下游系统都是 kafka(注:使用 kafka conector,它对部分系统做了适配,实现了 exactly once)。 生产者幂等性好做,没啥问题。
解决重复消费有两个方法:
- 下游系统保证幂等性,重复消费也不会导致多条记录。
- 把 commit offset 和业务处理绑定成一个事务。
本来 exactly once 实现第 1 点就 ok 了。 但是在一些使用场景下,我们的数据源可能是多个 topic,处理后输出到多个 topic,这时我们会希望输出时要么全部成功,要么全部失败。这就需要实现事务性。既然要做事务,那么干脆把重复消费的问题从根源上解决,把 commit offset 和输出到其他 topic 绑定成一个事务。
5. Ref
https://www.jianshu.com/p/d3e963ff8b70 https://www.cnblogs.com/wangzhuxing/p/10051512.html#_label1
