拜占庭将军问题
拜占庭将军问题最早是由Leslie Lamport与另外两人在1982年发表的论文《The Byzantine Generals Problem 》提出的, 他证明了在将军总数大于3f ,背叛者为f 或者更少时,忠诚的将军可以达成命令上的一致,即3f+1<=n。算法复杂度为o(n^(f+1))。
而Miguel Castro (卡斯特罗)和Barbara Liskov(利斯科夫)在1999年发表的论文《Practical Byzantine Fault Tolerance》中首次提出PBFT算法,该算法容错数量也满足3f+1<=n,算法复杂度为o(n^2)。
注:pbft算法的最大容错节点数量是(n-1)/3,而raft算法的最大容错节点数量是(n-1)/2
PBFT算法原理
PBFT是一种状态机副本复制算法,即服务作为状态机进行建模,状态机在分布式系统的不同节点进行副本复制。每个状态机的副本都保存了服务的状态,同时也实现了服务的操作。将所有的副本组成的集合使用大写字母R表示,使用0到|R|-1的整数表示每一个副本。
为了描述方便,通常假设故障节点数为f个,整个服务节点数为|R|=3f+1个,f是有可能失效的副本的最大个数。尽管可以存在多于3f+1个副本,但额外的副本除了降低性能外不能提高可靠性。
所有的副本在一个被称为视图(View)的轮换过程中运作。在某个视图中,一个副本作为主节点(primary),其它的副本节点作为备份节点(backups)。视图是连续编号的整数。主节点由公式p = v mod |R|计算得到,v是视图编号,p是副本编号,|R|是副本集合的个数。当主节点失效的时候就需要启动视图轮换过程。
PBFT基本流程
PBFT算法的基本流程主要有以下四步:
- 客户端发送请求给主节点
- 主节点广播请求给其它节点,节点执行PBFT算法的三阶段共识流程。
- 节点处理完三阶段流程后,返回消息给客户端。
- 客户端收到来自f+1个节点的相同消息后,代表共识已经正确完成。
PBFT核心三阶段流程
算法的核心三个阶段分别是pre-prepare阶段(预准备阶段),prepare阶段(准备阶段),commit阶段(提交阶段)。
图中的C代表客户端,0,1,2,3代表节点的编号,打叉的3代表可能是故障节点或者是问题节点,这里表现的行为就是对其它节点的请求无响应。0是主节点。
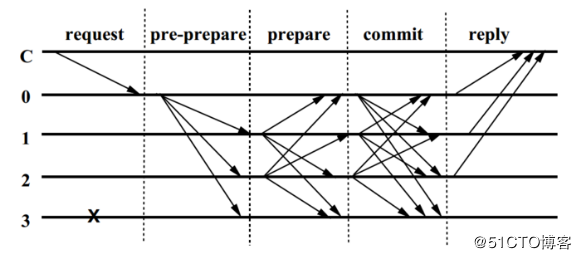
(1) request
客户端C向主节点p发送<REQUEST, o, t, c>请求。客户端会对请求进行签名。
- REQUEST:包含消息内容m,以及消息摘要d(m)
- o:请求的具体操作
- t:请求时客户端追加的时间戳
- c:客户端标识。
(2) pre-prepare
主节点收到客户端的请求,需要对客户端请求消息签名是否正确进行校验。非法请求则丢弃。正确请求,分配一个编号n,编号n主要用于对客户端的请求进行排序。
然后广播一条<<PRE-PREPARE, v, n, d>, m>消息给其它副本节点。并进行主节点签名。
- v:视图编号
- n:排序编号,n是要在某一个范围区间内的[h, H]
- d:客户端消息摘要
- m:消息内容
(3) prepare
副本节点i收到主节点的PRE-PREPARE消息,需要进行以下校验:
- 主节点PRE-PREPARE消息签名是否正确。
- 当前副本节点是否已经收到了一条在同一v下并且编号也是n,但是签名不同的PRE-PREPARE信息。
- d与m的摘要是否一致。
- n是否在区间[h, H]内。
非法请求则丢弃。正确请求,副本节点i向其它节点包括主节点发送一条<PREPARE, v, n, d, i>消息, v, n, d, m与上述PRE-PREPARE消息内容相同,i是当前副本节点编号。并进行副本节点i的签名
记录PRE-PREPARE和PREPARE消息到log中,用于视图轮换过程中恢复未完成的请求操作。PREPARE阶段如果发生视图轮换会导致丢弃PREPARE阶段的请求。
(4) commit
主节点和副本节点收到PREPARE消息,需要进行以下校验:
- 副本节点PREPARE消息签名是否正确。
- 当前副本节点是否已经收到了同一视图v下的n。
- n是否在区间[h, H]内。
- d是否和当前已收到PRE-PPREPARE中的d相同
非法请求则丢弃。如果副本节点i收到了2f+1个验证通过的PREPARE消息(包括PRE-PREPARE消息,以及自己),表明网络中的大多数节点已经收到同意信息,则向其它节点包括主节点发送一条<COMMIT, v, n, d, i>消息,v, n, d, i与上述PREPARE消息内容相同。并进行副本节点i的签名
记录COMMIT消息到日志中,用于视图轮换过程中恢复未完成的请求操作。记录其它副本节点发送的PREPARE消息到log中。COMMIT阶段用来确保网络中大多数节点都已经收到足够多的信息来达成共识,如果COMMIT阶段发生视图轮换,会保存原来COMMIT阶段的请求,不会达不成共识,也不会丢失请求编号。
(5) reply
主节点和副本节点收到COMMIT消息,需要进行以下校验:
- 副本节点COMMIT消息签名是否正确。
- 当前副本节点是否已经收到了同一视图v下的n。
- d与m的摘要是否一致。
- n是否在区间[h, H]内。
非法请求则丢弃。如果副本节点i收到了2f+1个验证通过的COMMIT消息,说明当前网络中的大部分节点已经达成共识,运行客户端的请求操作o,并返回<REPLY, v, t, c, i, r>给客户端。
r:是请求操作结果,客户端如果收到f+1个相同的REPLY消息,说明客户端发起的请求已经达成全网共识,否则客户端需要判断是否重新发送请求给主节点。记录其它副本节点发送的COMMIT消息到log中。
视图轮换(View Change)
如果主节点作恶,它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。备份节点应当有职责来主动检查这些序号的合法性。如果主节点掉线或者作恶不广播客户端的请求,客户端设置超时机制,超时的话,向所有副本节点广播请求消息。副本节点检测出主节点作恶或者下线,发起View Change协议。
垃圾回收
TODO
总结
- PBFT算法由于每个副本节点都需要和其他节点进行P2P的共识同步,因此随着节点的增多,性能会下降的很快,但是在较少节点的情况下可以有不错的性能,并且分叉的几率很低。
- PBFT主要用于联盟链,但是如果能够结合类似DPOS这样的节点代表选举规则的话也可以应用于公联,并且可以在一个不可信的网络里解决拜占庭容错问题,TPS应该是远大于POW的。
