1. XuperUnion
XuperUnion是超级链体系下的第一个开源项目,是构建超级联盟网络的底层方案。

2. 共识
2.1. 共识框架

上图是超级链共识模块的整体架构图,自底向上主要包括3层:
- 共识公共组件层:该层主要是不同共识可以共用的组件,包括共识公共节点Consensus、Interface、Chained-BFT、GPS原子钟等,它可以为链提供底层的共识安全性保障;
- 共识类型层:中间层为超级链以及支持或者即将支持的共识类型,主要包括TDPoS、Pow、授权共识等,基于底层的共识安全能力。在这一层,用户可以定义有自己特色的共识类型,如类似TDPoS这种选举机制的共识,也可以定义Stakeing等的相关逻辑;
- 可插拔共识层:最上层是可插拔共识的运行态,包括Step Consensus 和Pluggable Consensus两个实例,该层主要负责维护了链从创建到当前高度的共识的所有升级历史。
2.2. 多共识支持
共识引擎主要实现以下共识基础接口:
// ConsensusInterface is the interface of consensus
type ConsensusInterface interface {
Type() string
Version() int64
// 用于回滚或者重启时一些临时数据的恢复
InitCurrent(block *pb.InternalBlock) error
Configure(xlog log.Logger, cfg *config.NodeConfig, consCfg map[string]interface{}, extParams map[string]interface{}) error
// CompeteMaster 返回是否为矿工以及是否需要进行SyncBlock
CompeteMaster(height int64) (bool, bool)
// 节点收到一个区块验证其区块有效性
CheckMinerMatch(header *pb.Header, in *pb.InternalBlock) (bool, error)
// 开始挖矿前进行相应的处理
ProcessBeforeMiner(timestamp int64) (map[string]interface{}, bool)
// 用于确认块后进行相应的处理
ProcessConfirmBlock(block *pb.InternalBlock) error
// Get current core miner info
GetCoreMiners() []*MinerInfo
// Get consensus status
GetStatus() *ConsensusStatus
}
最关键的是:
- CompeteMaster:返回是否为矿工以及是否需要进行SyncBlock
- CheckMinerMatch:节点收到一个区块验证其区块有效性
- ProcessBeforeMiner:开始挖矿前进行相应的处理
- ProcessConfirmBlock:用于确认块后进行相应的处理
目前开源的共识有:

- POW
- Single:授权共识,在一个区块链网络中授权固定的address来记账本,一般在测试网使用。
- TDPoS:改进型的DPoS算法。
- TDPoS+Chained-BFT:验证节点轮值过程中,采取了 Chained-Bft 防止矿工节点的作恶。
2.3. 共识可插拔
XuperChain提供可插拔共识机制,通过提案和投票机制,升级共识算法或者参数。

共识可插拔是通过PluggableConsensus实现的,此模块会存储所有共识的升级历史,此历史会以StepConsensus结构的形式存储,如下:
// StepConsensus is the struct stored the consensus instance
type StepConsensus struct {
StartHeight int64
Txid []byte
Conn cons_base.ConsensusInterface
}
可以看到,主要就是记录哪个高度开始,使用了什么共识,然后在触发共识流程时,PluggableConsensus就会把调用相应共识的接口,以CompeteMaster为例:
// CompeteMaster confirm whether the node is a miner or not
func (pc *PluggableConsensus) CompeteMaster(height int64) (bool, bool) {
for i := len(pc.cons) - 1; i >= 0; i-- {
if height >= pc.cons[i].StartHeight {
return pc.cons[i].Conn.CompeteMaster(height) // 调用相应共识的CompeteMaster
}
}
return false, false
}
2.4. 共识主流程
主要逻辑在 core/xchaincore.go 文件中,其中与共识模块交互的函数主要有2个,分别是 Miner() 和 SendBlock() :
- Miner(): 这个函数的主要功能有2点,首先判断自己是否为当前的矿工,当判断自己是矿工时需要进行区块打包。
- SendBlock(): 这个函数是节点收到区块时的核心处理逻辑,当节点收到一个区块时会调用共识模块的相关接口进行区块有效性的验证,当验证通过后会将区块写入到账本中。
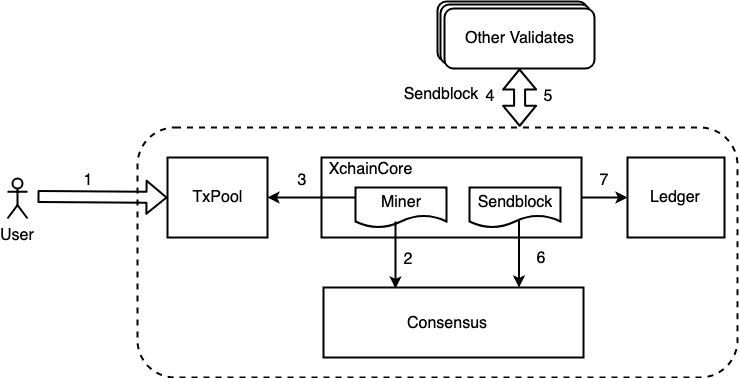
- 用户提交交易到网络,交易执行完后会进入未确认状态,并记录在交易的未确认列表中TxPool中;
- 节点的Miner流程通过访问Consensus模块判断自己是否为当前的矿工;
- 当节点判断自己是矿工时需要从TxPool中拉取交易并进行区块的打包;
- 当矿工完成打包后会将区块广播给其他的验证节点,同时会通过步骤7将区块写入到账本;
- 如果某个时刻其他节点判断自己是矿工,同样地会按照上述1-5流程进行区块打包,打包完后会将区块广播给该节点;
- 节点收到区块后,会调用consensus模块进行区块的有效性验证;
- 矿工打包完后或者验证节点收到一个有效的区块后,将区块写入账本;
3. TDPoS+Chained-BFT 共识的实现
3.1. 概述
- TDPoS是超级链的一种改进型的DPoS算法,他是在一段预设的时间长度(一轮区块生产周期)内选择若干个验证节点,同时将这样一轮区块生产周期分为N个时间段, 这若干个候选节点按照约定的时间段协议协同挖矿的一种算法。
- 在选定验证节点集合后,TDPoS通过Chained-BFT算法来保证轮值期间的安全性。

3.2. TDPoS
TDPoS是超级链的一种改进型的DPoS算法。
3.2.1. 节点角色
在TDPoS中,网络中的节点有三种角色,分别是“普通选民”、“候选人”、“验证者”。

3.2.2. 选民
所有节点拥有选民的角色,可以对候选节点进行投票;
3.2.3. 候选人
需要参与验证人竞选的节点通过注册机制成为候选人,通过注销机制退出验证人竞选;
提名为候选人会有很多规则,主要有以下几点:
- 提名候选人需要冻结燃料,并且金额不小于系统总金额的十万分之一;
- 该燃料会被一直冻结,直到节点退出竞选;
- 提名支持自提和他提,即允许第三方节点对候选人进行提名;
- 被提名者需要知晓自己被提名,需要对提名交易进行背书;
选举规则
候选人被提名后,会形成一个候选人池子,投票需要针对该池子内部的节点进行。TDPoS的投票也有很多规则,主要有以下几点:
- 任何地址都可以进行投票,投票需要冻结燃料,投票的票数取决于共识配置中每一票的金额,票数 = 冻结金额 / 投票单价;
- 该燃料会被一直冻结,直到该投票被撤销;
- 投票采用博尔达计分法,支持一票多投,每一票最多投给设置的验证者个数,每一票中投给不同候选人的票数相同;
候选人的提名和罢黜是通过智能合约实现的,主要有以下几个合约方法:
// 候选人投票撤销
revokeVoteMethod = "revoke_vote"
// 候选人提名
nominateCandidateMethod = "nominate_candidate"
// 候选人罢黜
revokeCandidateMethod = "revoke_candidate"
核心接口:
func (tp *TDpos) runVote(desc *contract.TxDesc, block *pb.InternalBlock) error {
// ......
return nil
}
func (tp *TDpos) runRevokeVote(desc *contract.TxDesc, block *pb.InternalBlock) error {
// ......
return nil
}
func (tp *TDpos) runNominateCandidate(desc *contract.TxDesc, block *pb.InternalBlock) error {
// ......
return nil
}
func (tp *TDpos) runRevokeCandidate(desc *contract.TxDesc, block *pb.InternalBlock) error {
// ......
return nil
}
func (tp *TDpos) runCheckValidater(desc *contract.TxDesc, block *pb.InternalBlock) error {
// ......
return nil
}
3.2.4. 验证者
每轮第一个节点进行检票,检票最高的topK候选人集合成为该轮的验证人,被选举出的每一轮区块生产周期的验证者集合,负责该轮区块的生产和验证,某个时间片内,会有一个矿工进行区块打包,其余的节点会对该区块进行验证。
生成验证人的核心逻辑如下:
(统计票数+排序)
// 生成当前轮的验证者名单
func (tp *TDpos) genTermProposer() ([]*cons_base.CandidateInfo, error) {
//var res []string
var termBallotSli termBallotsSlice
res := []*cons_base.CandidateInfo{}
// 统计票数
tp.candidateBallots.Range(func(k, v interface{}) bool {
key := k.(string)
value := v.(int64)
tp.log.Trace("genTermProposer ", "key", key, "value", value)
addr := strings.TrimPrefix(key, GenCandidateBallotsPrefix())
if value == 0 {
tp.log.Warn("genTermProposer continue", "key", key, "value", value)
return true
}
tmp := &termBallots{
Address: addr,
Ballots: value,
}
termBallotSli = append(termBallotSli, tmp)
tp.log.Trace("Term publish proposer num ", "tmp", tmp, "key", key)
return true
})
if int64(termBallotSli.Len()) < tp.config.proposerNum {
tp.log.Error("Term publish proposer num less than config", "termVotes", termBallotSli)
return nil, ErrProposerNotEnough
}
// 排序
sort.Stable(termBallotSli)
for i := int64(0); i < tp.config.proposerNum; i++ {
tp.log.Trace("genTermVote sort result", "address", termBallotSli[i].Address, "ballot", termBallotSli[i].Ballots)
addr := termBallotSli[i].Address
keyCanInfo := genCandidateInfoKey(addr)
ciValue, err := tp.utxoVM.GetFromTable(nil, []byte(keyCanInfo))
if err != nil {
return nil, err
}
var canInfo *cons_base.CandidateInfo
err = json.Unmarshal(ciValue, &canInfo)
if err != nil {
return nil, err
}
if canInfo.Address != addr {
return nil, errors.New("candidate address not match vote address")
}
res = append(res, canInfo)
}
tp.log.Trace("genTermVote sort result", "result", res)
return res, nil
}
在CompeteMaster中会判断当前是否是矿工:
// CompeteMaster is the specific implementation of ConsensusInterface
func (tp *TDpos) CompeteMaster(height int64) (bool, bool) {
sentNewView := false
Again:
t := time.Now()
un := t.UnixNano()
key := un / tp.config.period
sleep := tp.config.period - un%tp.config.period
maxsleeptime := time.Millisecond * 10
if sleep > int64(maxsleeptime) {
sleep = int64(maxsleeptime)
}
v, ok := tp.isProduce[key]
if !ok || v == false {
tp.isProduce[key] = true
} else {
time.Sleep(time.Duration(sleep))
goto Again
}
// 查当前时间的term 和 pos
t2 := time.Now()
un2 := t2.UnixNano()
term, pos, blockPos := tp.minerScheduling(un2)
// 查当前term 和 pos是否是自己
tp.curTerm = term
if blockPos > tp.config.blockNum || pos >= tp.config.proposerNum {
if !sentNewView {
// only run once when term or proposer change
err := tp.notifyNewView(height)
if err != nil {
tp.log.Warn("proposer or term change, bft Newview failed", "error", err)
}
sentNewView = true
}
goto Again
}
// reset proposers when term changed
if pos == 0 && blockPos == 1 {
err := tp.notifyTermChanged(tp.curTerm)
if err != nil {
tp.log.Warn("proposer or term change, bft Update Validators failed", "error", err)
}
}
// if NewView not sent, send NewView message
if !sentNewView {
// if no term or proposer change, run NewView before generate block
err := tp.notifyNewView(height)
if err != nil {
tp.log.Warn("proposer not changed, bft Newview failed", "error", err)
}
sentNewView = true
}
// master check
// 判断当前是否是矿工
if tp.isProposer(term, pos, tp.address) {
tp.log.Trace("CompeteMaster now xterm infos", "term", term, "pos", pos, "blockPos", blockPos, "un2", un2,
"master", true)
tp.curBlockNum = blockPos
s := tp.needSync()
return true, s
}
tp.log.Trace("CompeteMaster now xterm infos", "term", term, "pos", pos, "blockPos", blockPos, "un2", un2,
"master", false)
return false, false
}
而判断的依据有三个:
- term:第几轮
- pos:当前轮中是第几个验证者
- tp.address:当前地址
其中的term和pos是根据矿工调度算法得来的:
// miner 调度算法, 依据时间进行矿工节点调度
func (tp *TDpos) minerScheduling(timestamp int64) (term int64, pos int64, blockPos int64) {
if timestamp < tp.initTimestamp {
return
}
tp.log.Trace("getTermPos", "timestamp", timestamp, "inittimestamp", tp.initTimestamp)
// 每一轮的时间
termTime := tp.config.termInterval + (tp.config.proposerNum-1)*tp.config.alternateInterval +
tp.config.proposerNum*tp.config.period*(tp.config.blockNum-1)
// 每个矿工轮值时间
posTime := tp.config.alternateInterval + tp.config.period*(tp.config.blockNum-1)
term = (timestamp-tp.initTimestamp)/termTime + 1
resTime := (timestamp - tp.initTimestamp) - (term-1)*termTime
pos = resTime / posTime
resTime = resTime - (resTime/posTime)*posTime
blockPos = resTime/tp.config.period + 1
tp.log.Trace("getTermPos", "timestamp", timestamp, "term", term, "pos", pos, "blockPos", blockPos)
return
}
根据当前的时间即可知道当前是第几轮,当前轮中是第几个验证者,以及块高度。
这个算法的依据是TDPoS的时间片切分:

为了降低切主时容易造成分叉,TDPoS将出块间隔分成了3个,如上图所示:
- t1:同一轮内同一个矿工的出块间隔;
- t2:同一轮内切换矿工时的出块间隔,需要为t1的整数倍;
- t3:不同轮间切换时的出块间隔,需要为t1的整数倍;
3.2.5. Q&A
(1) 在TDPOS机制是怎么优化DPOS机制的分叉问题的?如果此时有一两个块由于网络延时其他节点未收到该广播,那是再发广播,等到其他节点确认收到该广播以后再切换BP节点?
主要是有以下2点:
- 首先在时间调度算法切片上,有3个时间间隔配置,分别为出块间隔、轮内BP节点切换的时间间隔和切换轮的时间间隔,这个其实很简单,这样在切换BP节点时会可以让区块有足够的时间广播给下一个BP;
- 在网络拓扑上进行的优化,超级节点的选举是在每轮的第一个区块,并且提前一轮确定,这时网络层有足够的时间在BP节点之间建立直接的链接,这样也可以降低我们切换BP节点的分叉率。
(1)TDPoS+Chained-BFT最终确认时间是多少?
3个块。(通过Chained-BFT实现)
3.3. Chained-BFT
超级链底层有一个共识的公共组件叫chained-bft,其是Hotstuff算法的实现。
3.3.1. HotStuff
HotStuff提出了一个三阶段投票的BFT类共识协议,该协议实现了safety、liveness、responsiveness特性。通过在投票过程中引入门限签名实现了O(n) 的消息验证复杂度。
对比下PBFT、Tendermint、hotStuff:
- PBFT: 两阶段投票,每个view有超时,viewchange通过一轮投票来完成,viewchange消息中包含了prepared消息(即达成了第一阶段投票的消息)。
- Tendermint: 两阶段投票,一个round中的各个阶段都有超时时间,roundchange通过超时触发(而不是投票),网络节点保存自己已经达成第一阶段投票的消息(即polka消息)。
- hotStuff: 三阶段投票,每个view有超时,采用阈值签名减小消息复杂度。liveness与safety解耦为两个部分
3.3.2. DPoS 3.0: Integrate DPoS with ChainedBFT
相关PR:
- DPoS 3.0: Integrate DPoS with ChainedBFT
- Consensus common module support chained-bft hotstuff
- Add safety rules for Chained-bft.
- Add QuorumCert in Block struct and add some unit test for chained-bft.
从相关PR中可以看出ChainedBFT对DPoS的增强主要体现在以下两个方面:
- 拜占庭容错:使用ChainedBFT使得网络能够容忍三分之一的拜占庭节点。
- 交易的确认:引入锁块机制,交易会被三个块锁住。
4. 参考资料
- 超级链共识框架:https://xuperchain.readthedocs.io/zh/latest/design_documents/consensus.html
- Chained-BFT共识公共组件:https://xuperchain.readthedocs.io/zh/latest/design_documents/chained_bft.html
- TDPoS共识:https://xuperchain.readthedocs.io/zh/latest/design_documents/tdpos.html
